
Incomplete Supervision:
Text Classification based on a Subset of Labels
Yacun Wang, Luning Yang
Mentor: Jingbo Shang
About our project
Many text classification models rely on the assumption that requires users to provide the model with a full set of class labels. This is not realistic, as users may not be aware of all possible classes in advance, or may not be able to obtain an exhaustive list. These models also forced to predict any new document to one of the existing classes, where none of the existing labels is a good fit. Thus, we explore the Incomplete Text Classification (IC-TC) setting: Models mine patterns in a small labeled set which only contains existing labels, apply patterns to predict into existing labels in an unlabeled set, and detect out-of-pattern clusters for potential new label discoveries. We experiment with the potential of weakly supervised ML to detect class labels that humans may not recognize, thus facilitating more accurate classification. From the document and class embeddings and unconfident documents generated, we found that both the baseline and the final model had some capability of detecting unseen classes, and label generation techniques help produce reasonable new class labels.
Disclaimer
Due to space limitations, please view all cited papers in the report.
Introduction
In recent years, with the growing complexity and scale of neural network models, they also require more high-quality human-annotated training data to achieve satisfactory performances. These actions usually require extensive domain expertise and are extremely time-consuming. Researchers have strived to develop models in the weak supervision setting that aim to gradually alleviate the human burden in creating such annotations for the documents. In particular, researchers have approached the problem of text classification by developing models that only require the class labels and a little extra information for each class label such as (1) a few representative words (i.e. seed words); (2) authors, publication date, etc. (i.e. metadata). Researchers have shown that models are capable of obtaining reliable results without full human annotation.
However, the problem setting for these models all depend on one key assumption: users need to provide the model with a full set of desired class labels for the model to consider. This is less realistic as users might not know all possible classes in advance; users are also unable to obtain an exhaustive list of class names without carefully reading and analyzing the documents. If some documents happen to fall outside of the given list, the models will be forced to predict to one of the existing classes based on normalized probability (e.g. the last softmax layer for a neural network).
For example, an online article database might contain thousands of user-uploaded articles labeled with their domains: news, sports, computer science, etc., and the labels are only limited to existing articles. When trying to classify new documents, there might be some classes existing in our documents whose labels are not provided by our database. For instance, we may have a group of articles in the domain of chemistry, while we don’t have the exact label “chemistry” in the database yet.
In this paper, we explore the Incomplete TextClassification (IC-TC) setting: Models mine patterns in a small labeled set which only contains existing labels, apply patterns to predict into existing labels in an unlabeled set, and detect out-of-pattern clusters for potential new label discoveries. We try to explore the possibility of utilizing the power of machines to detect class labels that humans fail to recognize and classify documents to more reasonable labels. In particular, we proposed a baseline model and an advanced model that both leverage semi-supervised and unsupervised learning methods to extract information from the labeled part of the dataset, learn patterns from the unlabeled part, and generate new labels based on documents that have lower similarity between their representation and existing class labels. From the experiments on a well-balanced dataset, both models are performing relatively well in learning high-quality seed words, word embeddings, class and document embeddings, and detecting unseen clusters of classes. With the help of modern large language model ChatGPT, the models are also capable of finding generic labels for the new classes.
Data
DBPedia
Evaluation
New Label Binary
The model decides on whether to generate new labels for a document based on the confidence of weak supervised document-class representations. The sub-task of predicting whether a document falls outside of existing classes is a binary classification prediction. We evaluate this sub-task using binary precision and recall, with new labels necessary as the positive class.
Existing Performance
The multi-class classification result of all documents with ground truth as existing labels. Report micro- and macro-F1.
New Label Quality
After new labels are generated, we inspect the quality of new labels using either manual inspection, and plot word clouds comparing the significant words appeared in the original removed classes and the new clustered classes with generated labels.
Method Overview
Module

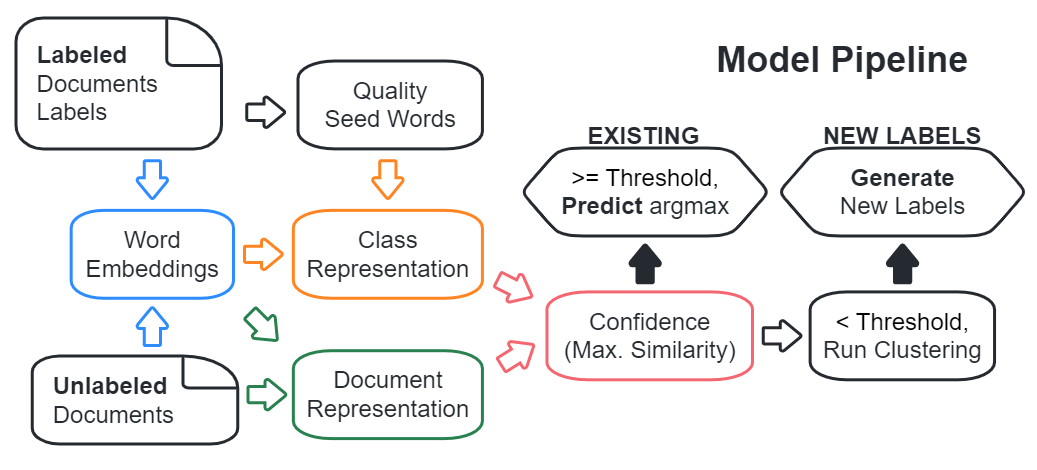
Figure 1: Model Pipeline Illustration
Figure 1 illustrates the model pipeline for both of the baseline and the final models. The models for the incomplete setting start from a set of labeled documents and another set of unlabeled documents, and mainly contain 4 modules: (1) learning word embeddings from the documents; (2) using word embeddings to find document and class representations; (3) confidence split based on document-class similarity; (4) clustering unconfident documents and generate new labels.
Final Model
The final model fills in the remaining slots of the model pipeline by using:
Result
Summary of Findings
We report the results of the final model, by the same order as the pipeline shows:

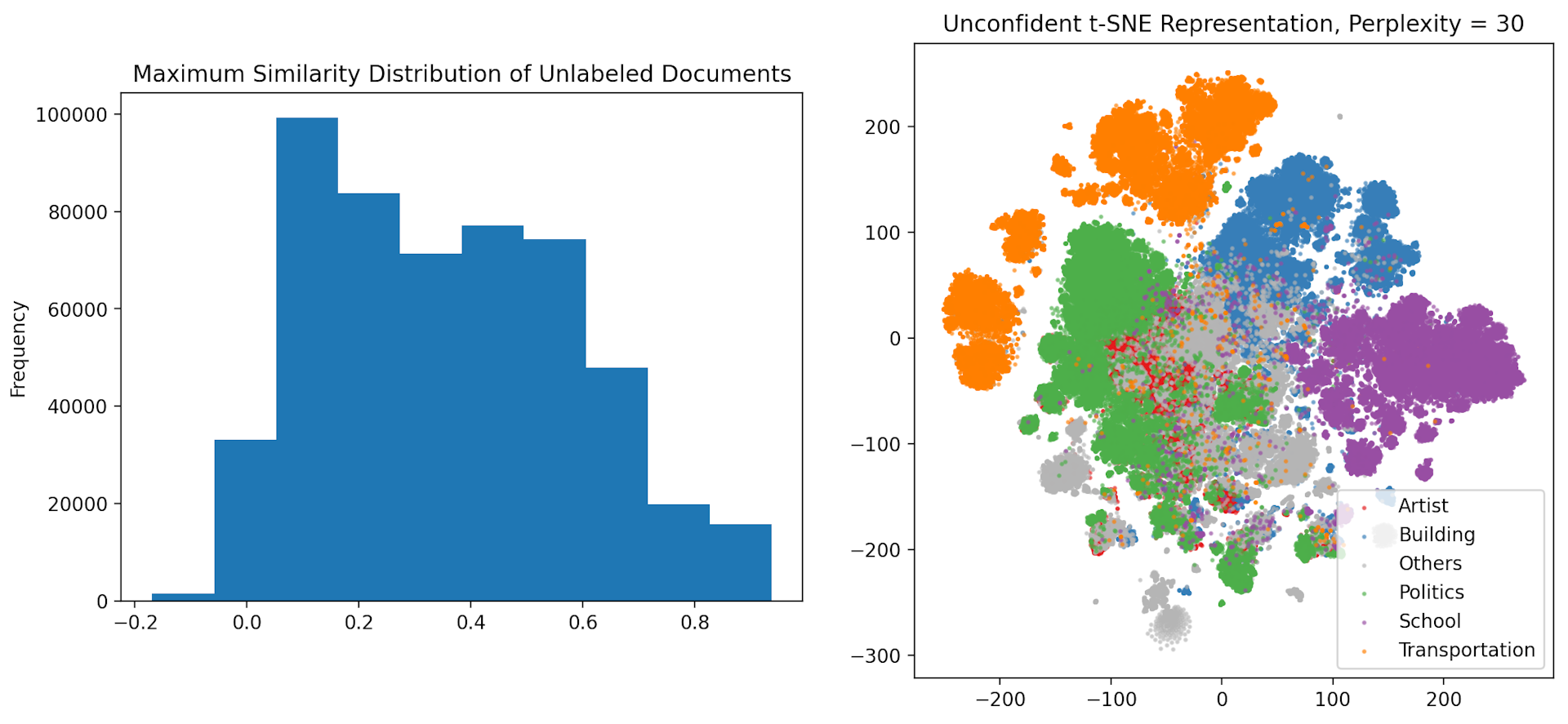
Figure 2: Maximum Similarity Distribution for Unlabeled Documents Figure 3: t-SNE Dimensionality Reduction for Unlabeled Documents

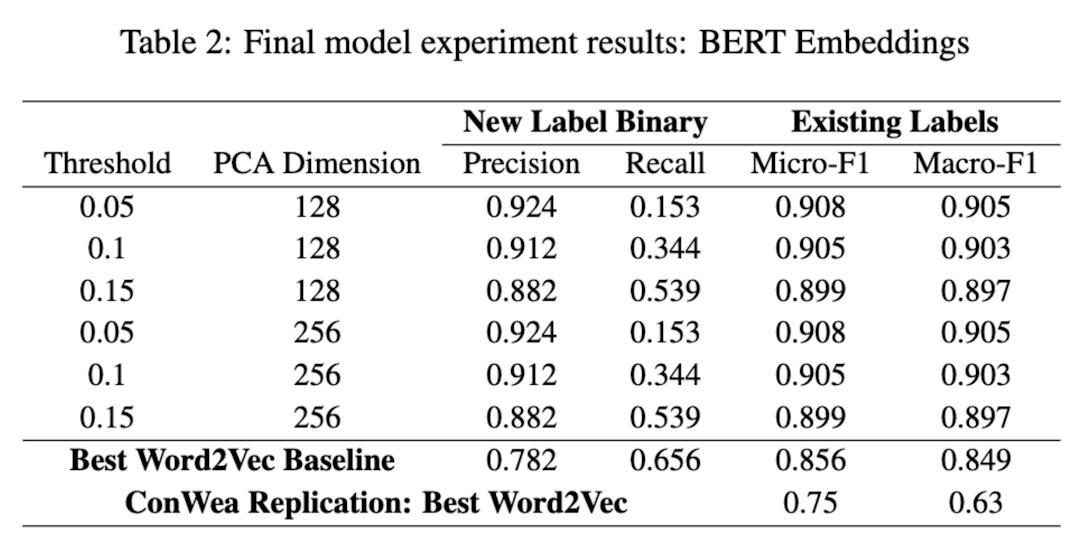
The word cloud of each removed class and clustered class is plotted in Figure 4. From the label comparison and the word cloud, most important words show in aligned clusters, confirming that the clusters found are relatively close to the original classes. It also lays a good foundation for label generation. In addition, ChatGPT also produces reasonable generic labels for the clusters.


Figure 4: Word cloud for removed and generated labels, with manual row alignment. Note they don’t necessarily match.
Future Work
From the discussions above, although the current final model is capable of finding quality representations, perform reasonable similarity-based confidence splits, and generate labels based on clusters, there are plenty of drawbacks that this model failed to address:
Contact
Yacun Wang
- yaw006@ucsd.edu
- Github
- colts661
Luning Yang
- l4yang@ucsd.edu
- Github
- Luning-Yang